Interesting paper (go to the full one for all the details) which shows that with the current architecture it's really hard if not impossible to make safe systems with LLMs. This gives interesting insights in the weird form of proto-cognition those models exhibit.


More reasons why the whole "data centers in space idea" is stupidly dangerous and likely unreachable.

Remind me how your built your models in the first place? Yeah right...
Very sobering opinion piece. For all the talks about a China / USA race, it feels more like two flavors of the same dystopia. The race is just here to justify acting against their own population interest. The result is then the increase in illiberal fixations and nihilistic world views. This can't end well.
Some news from the Apertus project, they released smaller models. Interesting work.

This is an interesting proposal, let's hope it gets picked up and appear in more licenses.
A very balanced set of recommendations from the SFC around LLM uses. It's just the beginning and still lacks a bit in details. It's very welcome though and I look forward to their updates.
What happens when targeted scams become cheap to run? This covers it fairly well, and we need to change our heuristics and trust model.
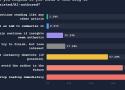
Badly apparently, looks like it makes for prose people avoid. Now the thing is... with the widespread suspicion, some people might be wrongfully flagged as using LLM to write their posts.
What a surprise... It turns out it's very easy to manipulate AI "search". Something which operates of statistical similarity to queries, who knew it could be manipulated. 🙄
The latest move by the US government treating LLMs like dangerous weapons tells something about the geopolitical moment. Can we collectively raise to the challenge and build on cooperation instead? It'd be a much better position than assuming governments or big companies will make the right choices for everyone else in isolation.

Long, rich, and sourced piece. Or why the current gold rush aims at accelerating wealth accumulation of a few to the expense of everyone else. If the plans work as intended, the outcome won't look good.
This piece asks a very profound question in fact. If you're in a workplace where senior management allows and pushes everyone to get deluded about the real capabilities of those tools, how do you later move forward and rebuild trust?
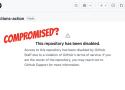
There's really something nasty at play. Those coding agents are clearly not insulated from the system enough and to easy to manipulate to exfiltrate sensitive information.
A good primer on the main architecture traits of transformer models.
Indeed the trend wasn't new. It's "just" the icing on the cake from the enclosure point of view.
When Amnesty International feels like it has to publish a 44 pages briefing pointing out what's wrong with your approach and business... it'd be nice to pay attention.
Very interesting take. This gives very valid ground on why tech communities should reject AI based contributions. Not doing so will indeed hinder the commons communities rely on to exist and improve. This is a path to prevent getting better at inclusivity and diversity (which is really needed).

This is clearly the Ouroboros moment in our industry. People pushing for such restructuring and layoffs are drinking the kool-aid and will ultimately be responsible for killing what put them there in the first place.
I mean, with the announced productivity gains of generative AI... It doesn't feel like a big ask. 😜