Interesting, it confirms garbage collectors can be the source of unrecoverable performance degradation in request based systems.


Or why anticipating too much is merely a gamble. You can be lucky, but how often will you be? Also I agree that in such cases the performance will be impacted longer term leading to a death by thousands of paper cuts.
Compile time reflection in C++ will indeed be a big deal.
Interesting dive into some of the performance improvements introduced into recent CPython releases.
Interesting experiment showing that BLOBs in a database can be a good alternative to individual files on a filesystem in some contexts.
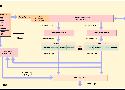
Interesting article about what's coming for the branch predictor in the Zen 5 architecture from AMD.
A paper listing patterns to reduce latency as much as possible. There are lesser known tricks in there.
Another interesting algorithm to handle using SIMD.
Forced to use UUID as primary key in a table? Then make sure to use them properly to not kill the performance more than necessary. Ideally use something else though.
There’s plenty of room at the Top: What will drive computer performance after Moore’s law? | Science
As Moore's law fades away this question is indeed essential. Looks like there will be more pressure on software and algorithms than before (at last one might say, we had decades of waste there). Streamlining hardware architectures will have a role too, we might see simpler cores in greater numbers.
Interesting case, when everything else gets faster, memory copies might start to become the bottleneck.

Interesting dive into how join() and generator behave in CPython.
The ordering used for matrix multiplications definitely matters.
SIMD keeps providing interesting performance boosts for parsing work loads.
Another good example of how to speed up some Python code with nice gains.
Definitely to keep in mind when using sampling profilers indeed. They're useful, they help to get a starting point in the analysis but they're far from enough to find the root cause of a performance issue.

Interesting how much extra performance you can shave off the GPU by going back to how the hardware works.

Interesting quick comparison, this shows the design tradeoffs quite well.
Interesting use of database templates and memory disks to greatly speed up test executions.
More work about eco-design of software. This is definitely welcome. I found this work a bit weak on the state of the art and the interview parts (10 people in the same company). But the field is so nascent that it's to be expected I guess, PhD students have to do with what they have access to. Unsurprisingly this shows a great lack of proper tools to tackle the measurement problem. This thesis shows interesting prospects to reduce variations in measurements though, some of the proposed guidelines might help but cannot offset the hardware heterogeneity completely... The parts focusing on practical advices around Java use and deployment are interestingly easy to apply though. You need to take into account the context of your application to make the right choices of course.