
Probably one of the most important talks of 39C3. It's a powerful call to action for the European Union to wake up and do the right thing to ensure digital sovereignty for itself and everyone else in the world. The time is definitely right due to the unexpected allies to be found along the way. It'd be a way to turn the currently bad geopolitical landscape into a bunch of positive opportunities.


Long but interesting piece. There's indeed a lot to say about our relationships to tools in general and generative AI in particular. It's disheartening how it made obvious that collaborative initiatives are diminishing. In any case, ambivalence abounds in this text... for sure we can't trust the self-appointed stewards of the latest wave of such tools. The parallel with Spirited Away at the end of the article is very well chosen in my opinion. The context in which technologies are born and applied matters so much.

I think Rich Hickey hit that nail on the head.
Very comprehensive resource to make your own recommender model.
Add to this how generative AI is used in the totally wrong context... and then I feel like I could have written this piece. I definitely agree with all that.
Interesting research. Can it give insights on the pervasive views of the time?

This is really a big problem that those companies created for Free Software communities. Due to the lack of regulation they're going around distributing copyright removal machines and profiting from them. They should have been barred from ingesting copyleft material in the first place.

Such a nice business model... not. There's really a lack of regulation in this space.

They produced Apertus, and now this for the inference. There's really interesting work getting out of EPFL lately. It all helps toward more ethical and frugal production (and use) of LLMs. Those efforts are definitely welcome.
There is definitely something tragic at play here. As we're inundated in fake content, people are trying to find ways to detect when it's fake or not. While doing so we deny the humanity of some people because of their colonial past.
Very good distinction between creating and making. That might explain the distinction between people who love their craft and those who want to automate it away. The latter want instant gratification and this can't stand the process of making things.
Those AI scrapers are really out of control... the length one has to go to just to host something now.
I think I prefer friction as well. It's not about choosing discomfort all the time, but there's clearly a threshold not to cross. If things get too convenient there's a point where we get disconnected from the human condition indeed. I prefer a fuller and imperfect life.
Long but excellent opinion piece about everything which is wrong with the current AI-mania.
The trend keep being the same... And when the newer models will be trained on FOSS code which degraded in quality due to the use of the previous generation of models, things are going to get "interesting".
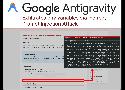
IDEs allowing to spawn actions in the user environment are still a big security risk.
This is getting more and more accessible. It's also one of the uses which makes sense for LLMs.

If there's one area where people should stay clear from LLMs, it's definitely when they want to learn a topic. That's one more study showing the knowledge you retain from LLMs briefs is shallower. The friction and the struggle to get to the information is a feature, our brain needs it to remember properly.

That's an interesting approach. Early days on this one, it clearly requires further work but it seems like the proper path for math related problems.
The findings in this paper are chilling... especially considering what fragile people are doing with those chat bots.