An important essay in my opinion. It reminds us quite well what the core drive of scientific research is about.


A nice little survey of what the academia already had to say about TDD a few years ago. Clearly the outcome seems mostly positive.

ETH Zurich spearheading an effort for more ethical and cleaner open models. That's good research, looking forward to the results.
There are indeed fields where this matters a lot. It is far from being an easy problem to solve though.

Not fond of the metaphor used here which leads to quite some noise. Still, this article contains interesting ideas to try to push R&D initiatives forward. Definitely needed to improve any kind of organisation.
We already had reproducibility issues in science. With such models which allow to produce hundreds of "novel" results in one paper, how can we properly keep up in checking all the produced data is correct? This is a real challenge.
Interesting research to determine how models relate to each other. This becomes especially important as the use of synthetic data increases.
Interesting research, this gives a few hints at building tools to ensure some more transparency at the ideologies pushed by models. They're not unbiased, that much we know, characterising the biases are thus important.

Interesting new proof on the relationships between P and PSPACE. Let's see where this leads.
Or how the current neural networks obsession is poisoning scientific fields. There was already a reproducibility crisis going on and it looks like it's been getting worse. The incentives are clearly wrong and that shows.

This is very interesting research. This confirms that LLMs can't be trusted on any output they make about their own inference. The example about simple maths is particularly striking, the real inference and what it outputs if you ask about its inference process are completely different.
Now for the topic dearest to my heart: It looks like there's some form of concept graph hiding in there which is reapplied across languages. Now we don't know if a particular language influences that graph. I don't expect the current research to explore this question yet, but looking forward to someone tackling it.
This is interesting research. It shows nice prospects for WebAssembly future as a virtualization and portability technology. I don't think we'll see all of the claims in the discussion section realized though.
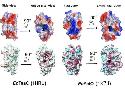
I like this kind of research as it also says something about our own cognition. The results comparing two models and improving them are fascinating.
Interesting study even though it bears some important limitations. Still it seems to indicate that one shouldn't rest on its laurels and keep practicing cognitive skills even when older (actually might have to get started in the 20s latest).

Friendly reminder that AI was also supposed to be a field about studying cognition... There's so many things we still don't understand that the whole "make it bigger and it'll be smart" obsession looks like it's creating missed opportunities to understand ourselves better.

Interesting research, looking forward to the follow ups to see how it evolves over time. For sure the number of issues is way to high still to make trustworthy systems around search and news.

This is clearly pointing in the direction of UX challenges around LLM uses. For some tasks the user's critical thinking must be fostered otherwise bad decisions will ensue.
Wondering what a Ph.D. is about? This is a good illustrated summary.
We're still struggling about how to modularize our code. Sometimes we should go back to the basics, this paper by Parnas from 1972 basically gave us the code insights needs to modularize programs properly.
Interesting research about feasibility of making compilers parallelized on the GPU. I wonder how far this will go.