
Chatbots can be useful in some cases... but definitely not when people expect to connect with other humans.


Another cruel reminder that basic reasoning is not to be expected from LLMs. Here is a quote from the conclusion of the paper which makes it clear:
"We think that observations made in our study should serve as strong reminder that current SOTA
LLMs are not capable of sound, consistent reasoning, as shown here by their breakdown on even such a simple task as the presented AIW problem, and enabling such reasoning is still subject of basic research. This should be also a strong warning against overblown claims for such models beyond being basic research artifacts to serve as problem solvers in various real world settings, which are often made by different commercial entities in attempt to position their models as a strong mature product for end-users. [...] Observed breakdown of basic reasoning capabilities, coupled with such public claims (which are also based on standardized benchmarks), present an inherent safety problem. Models with insufficient basic reasoning are inherently unsafe, as they will produce wrong decisions in various important scenarios that do require intact reasoning."
Definitely this, it's not the first time we see such a hype cycle around "AI". When it bursts the technology which created it is just not called "AI" anymore. I wonder how long this one will last though.

No, your model won't get smarter just by throwing more training data at it... on the contrary.

This is indeed sad to see another platform turn against its users. This was once a place to nurture young artists... it's now another ad driven platform full of AI made scams.
Definitely too much hype around large models right now. This over shadows the more useful specialized models.

Open is unsurprisingly only in the name... this company is really just a cult.
The training dataset crisis is looming in the case of large language models. They'll sooner or later run out of genuine content to use... and the generated toxic waste will end up in training data, probably leading to dismal results.

Interesting how much extra performance you can shave off the GPU by going back to how the hardware works.
Interesting questions and state of the art around model "unlearning". This became important due to the opacity of data sets used to train some models. It'll also be important in any case for managing models over time.
Nice article. It's a good reminder that the benchmarks used to evaluate generative AI systems have many caveats.

Interesting take on why people see more in LLM based systems than there really is. The parallels with psychics and mentalists tricks are well thought out.
This is how it should be done. This one comes with everything needed to reproduce the results. This is necessary to gain insights into how such models work internally.
Wondering how one can design a coding assistant? Here is an in depth explanation of the choices made by one of the solutions out there. There's quite some processing before and after actually running the inference with the LLM.
All the good reasons why productivity increases with code assistants are massively overestimated. To be used why not, but with a light touch.
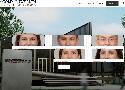
AI supercharged scam. I guess we'll see more of those.

You should be mindful of the dependencies you add. Even more so when the name of the dependency has been proposed by a coding assistant.

Excellent work to improve Llama execution speed on CPU. It probably has all the tricks of the trade to accelerate this compute kernel.

Smaller models with smarter architectures and low-bit quantized models are two venues for more efficient use. I'm really curious how far they'll go. This article focuses on low-bit quantized models and the prospects are interesting.
Wondering where some of the biases of AI models generating images come from? This is an excellent deep dive into one of the most successful data sets used to train said models. And they've been curated by... statistical models not humans. This unsurprisingly amplifies biases all the way to the final models.
This is an excellent piece, I highly recommend reading it.